Monitoring provides answers to known problems, while observable software allows developers to ask new questions to debug problems and gain insight into the general state of a dynamic system that is constantly changing in its complexity and unknown permutations. When observability goes well, monitoring gives you greater operational visibility, resulting in shorter incidents, fewer quality problems, better products, and more satisfied customers.
Your company will have unique observation needs, which means that your approach to your observation strategy will be unique. If you are still in the early days of your transition to monitoring and observability, you can take a service-based approach to monitoring certain parts of your ecosystem, rather than focusing on individual incidents.
The true value of observability is the ability to ensure visibility of overall topics such as measuring user experience, performance, SLOs, and other key metrics that are important to the company. Simply put, observability can be achieved if data is made available about the systems you want to monitor. If you make a system observable, you can collect data and use monitoring tools to perform analyses.
Without meaningful analysis, the purpose of creating observability by means of surveillance is missing. The better your analytical capacities, the more valuable your investments in observability and monitoring become.
The line between observability and surveillance can become blurred for development teams. Nowadays, observability seems to be a buzzword, but in fact it drives the surveillance process. In this paper we will discuss monitoring and observability as well as the relationship between the two.
The solution to the complexity of the modern development environment lies in observability. Monitoring and monitoring systems play a crucial role in achieving system reliability, but they are not the same. Let us understand the difference between observability, monitoring, and why they are critical for visibility and control in enterprise cloud-based IT operations.
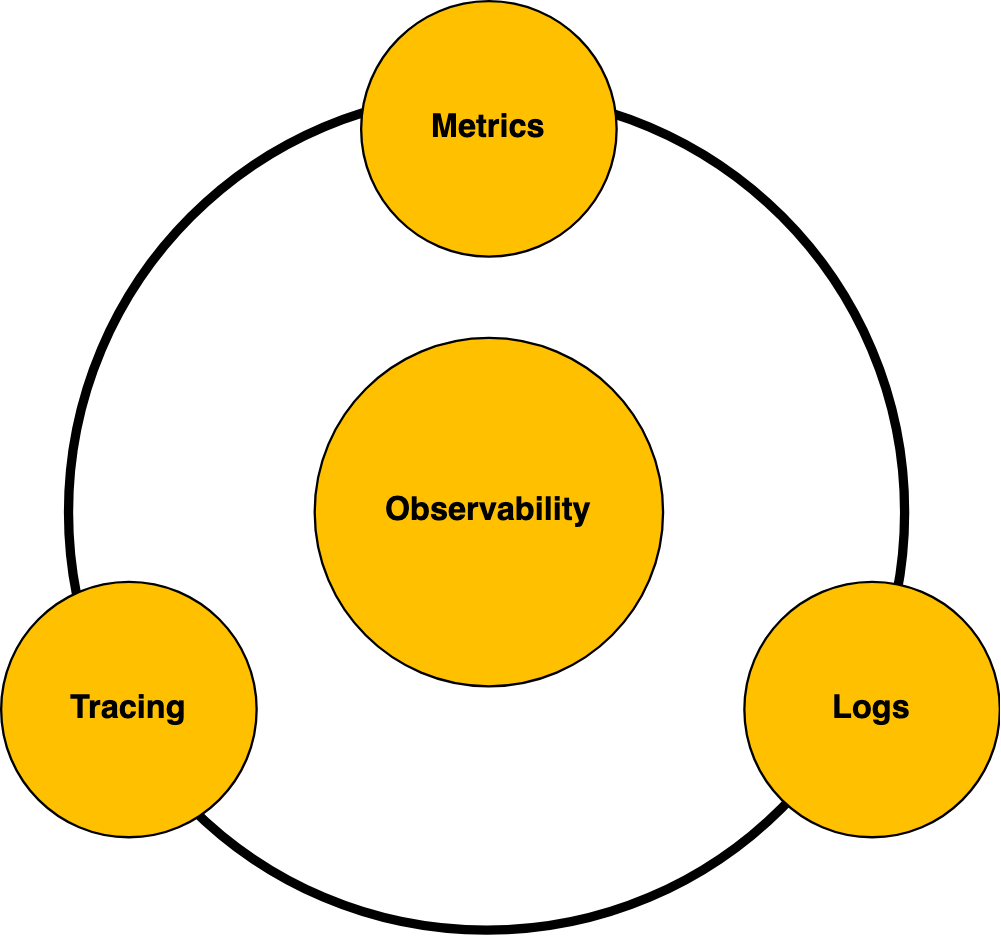
The three determining pillars of observability are
- Logging,
- Measurement
- Traceability
Based on measurement practice, you can track every step of the CI / CD pipeline and gain insights into the health, performance and reliability of your infrastructure and applications. If you are looking for a way to anticipate risks and solve problems before they escalate, pipeline observations will give your teams a better chance to collaborate, allowing you to identify issues in their code and ensure that they are resolved quickly.
In my opinion, this definition is suitable for companies on the planetary scale (such as Google, Facebook, and Twitter) and engineers of smaller organizations that need to find a new scorecard for observability. Charities, major CEOs, and Honeycomb list pre-set tools that set a set of technical specifications for observability. Despite the widespread adoption of this definition, there are counter-arguments that it is too narrow, and that there is a broader definition of observability than tools alone.
In our experience, the DevOps and SRE platform teams are the primary owners of the observation system because they manage it and set the policies. Various engineering teams that develop features and capabilities use it to gain visibility in their micro-services and apps, but do not have the general availability KPIs. It’s because we forget that the services they develop work as part of larger full-of-service apps that depend on other DevOps teams.
When surveying digital services, observability is a tool to identify the underlying causes and raise red flags. It tracks output, evaluates system performance, and tracks the state and behavior of the system. In this way, it can detect problems before they occur, even if they are unforeseen.
The concept of observability is particularly pronounced in DevOps and Software Development Lifecycle (SDLC) methodologies. As the name suggests, observability provides an excellent way to observe things that cannot be identified by the system: correctness checks, tests, monitoring and predictable errors. The observability shows the current state of the systems and provides unforeseeable failures that are not monitored or tested.
In early waterfall and agile frameworks, developers developed new features and product lines with separate test and operation teams to test software for reliability. This tacit approach meant that infrastructure, operations, and monitoring activities were outside the realm of development. Today monitoring objectives are not limited to collecting and processing log data and metrics, and distributed event tracking monitoring is used to observable systems.
Observability is based on the study of properties and patterns that have not been defined in advance. Monitoring tools and technical solutions enable teams to monitor and understand the state of their systems. Observability Tooling is a technical solution that allows teams to debug their systems more efficiently.
Observable systems allow you to understand and measure the inside of a system as you navigate through the effects of a complex microservice architecture. Observability has its origins in control theory, which measures how well one understands the internal state of a system and its external results.
Observability and surveillance complement each other, but each serves a different purpose. Remember that surveillance is an excellent mechanism for knowing the current and historical state of a distributed system. Monitoring information can help us identify problems, causes of errors, decision-making, faults, pattern analysis, and many other functions that are useful to all stakeholders at different stages.
Observability is a hot topic at the moment, sparking a lot of debate and argument about how observability differs from surveillance. Observability is not surveillance, surveillance is not observability, surveillance and observability are supersets.
Data observability is an ability for organizations to better understand the state of data in their systems, eliminate data downtime, and apply DevOps best practices to data pipeline observability. Similar to how DevOps is applicable to the observability of software, I think it is time to apply the same comprehensive care to data.
On the surface there will always be data problems and incidents, but the five pillars of data observability provide the holistic framework that is needed for true end-to-end reliability. Unlike traditional DevOps observation tools, the best data observatory solutions not only monitor these columns, but also prevent bad data from entering the columns in the first place. Data observability is an ability for organizations to understand the health of data in their systems and, like DevOps counterparts, can be used for automated monitoring, alerting and triaging to identify and evaluate data quality and traceability problems resulting in healthier pipelines, more productive teams and happier customers.