Republished from https://hackernoon.com/vibe-coding-has-a-step-sister-and-shes-coming-for-your-cicd
Vibe coding is everywhere. Talk to an LLM, get code, ship it. The problem is not generating the code – it is trusting it in production.
Jordi Cabot proposed a smart path: vibe modelling. Instead of asking an LLM for code, you ask it for models – class diagrams, state machines, structured representations a human can actually read and validate. Once the model checks out, a deterministic code generator takes over. He later extended this into vibe-driven engineering, where models remain the backbone even when AI is involved at every step of development.
Both sit within the practice of Model-Driven Engineering (MDE) – the idea that any software artifact can be formally described as a model, and concrete outputs are generated from it via a defined transformation chain. Every software project that ships needs a CI/CD pipeline – making it the place where a working model-driven transformation chain would help the most. Yet building that chain remains out of reach for most teams.
That is the gap this post is about.
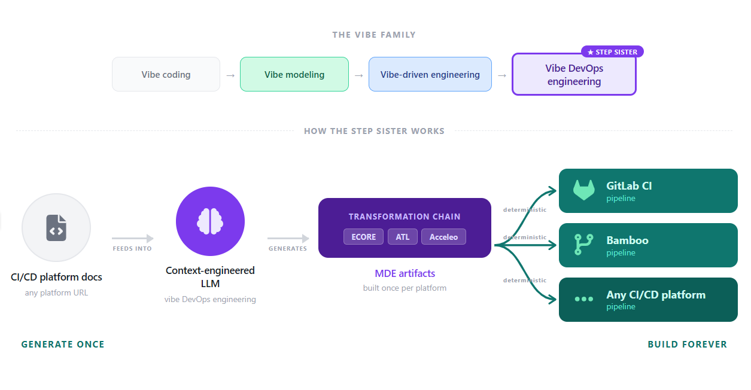
What is vibe DevOps engineering?
Adding a new CI/CD platform means writing new pipeline files. Every project. Every time. Then the platform updates. The pipeline breaks. You fix it. Another project using the same setup breaks. You fix that too. And the next one. Similar concepts appear across dozens of pipelines, but each one must be touched individually. Every new platform resets the clock. Every update ripples through the entire portfolio.
The smarter approach is Model-Driven Engineering. Build the transformation chain once – the metamodels that describe the platform, the transformation rules that map concepts, and the code generation templates that produce the files. Update the chain, regenerate everything. The problem is that building that chain requires deep expertise in MDE. Most teams do not have it, so it never gets developed.
Vibe DevOps engineering changes that. It uses context-engineered LLMs to generate that MDE transformation chain automatically. Point the system at the new platform’s documentation. It produces three artifacts: a platform-specific metamodel extension (ECORE), a model-to-model transformation (ATL), and a code generation template (Acceleo). Those artifacts then drive deterministic pipeline generation for any software project on that platform.
This is different from vibe coding because the LLM does not generate pipeline files directly. It generates the MDE transformation chain. The chain then generates the pipeline files. This keeps the final output deterministic and correct by construction.
This is also different from vibe-driven engineering. Where vibe-driven model-based engineering targets domain models and application code, vibe DevOps engineering targets transformation artifacts – formal, tool-specific constructs that must satisfy strict syntactic rules enforced by Eclipse ATL and Acceleo processors. Getting them wrong does not produce a bad model. It produces a runtime crash. When that happens, the error is encoded as a constraint and fed into the next generation round. Each failure sharpens the system.
A 2025 JetBrains survey found that 32 percent of organizations run two CI/CD tools in parallel. Nine percent run at least three. The problem does not appear once. It multiplies. So we tested it.
Does this actually work?
In our first experiments, we ran the three-step chain across three CI/CD platforms: GitLab CI, Atlassian Bamboo, and Azure DevOps. At each step, the generated artifact was checked against a pass criterion; the metamodel had to load in Eclipse without errors, the ATL transformation had to execute without runtime failures, and the generated YAML had to be syntactically valid. When a step failed, we identified the root cause, added exactly one new constraint to the prompt, and restarted the loop. Each such attempt is what we call a round. Fewer rounds mean less effort to reach a correct result.
GitLab CI was where we learned the most. The LLM generated ATL code that looked correct but used OCL constructs that the Eclipse ATL engine does not support. For example, the AND operator does not short-circuit in ATL. Using “->max()” causes a runtime failure. Reserved keywords like “def”, “rule”, and “module” cannot be used as variable names. Each of these failures had to be discovered, analysed, encoded as a constraint, and added to the next prompt. Each finding became a constraint for the next round.
One discovery stood out. A constraint about reserved keywords kept being violated – until we moved all constraints to appear immediately before the generation task in the prompt. The violation stopped. Where you place an instruction matters as much as what it says.
The second platform, Bamboo, needed only 6 rounds. All constraints from GitLab CI were loaded from the start. None of the previously seen errors appeared. The third platform, Azure DevOps, needed only 5 rounds. The constraint library from the first two runs transferred cleanly.
Across all three runs, 14 platform-agnostic constraints were collected. These constraints are not about CI/CD concepts. They are about how the Eclipse ATL and Acceleo processors behave. Any future platform run can pre-load them from round one.
All generated artifacts are available in the project repository: https://github.com/modeldrivendevopsai/mddoai
What about concept coverage?
Coverage was measured across nine DevOps PIM concepts from Flores et al.’s two-level model-driven approach. An LLM-as-a-Judge assessment rated each generated construct as Full, Partial, or None.
Core concepts like Pipeline, Job, Agent, and Expressions performed well across all three platforms. Triggers and Steps showed partial results on every platform. Some gaps came from platform limitations, not generation errors. Bamboo has no native Matrix construct. Azure DevOps has no native Services construct. These gaps are identifiable from documentation before generation starts.
No round addressed a misunderstanding of CI/CD concepts. Every error was about tool syntax in ATL or Acceleo. The LLM knows DevOps. It just needs grounding in MDE tooling conventions.
What makes this different from just prompting an LLM?
Generating the transformation chain happens in three steps. Step 1 produces the platform-specific metamodel extension – the ECORE file describing the new platform’s concepts. Step 2 produces the ATL transformation – rules that map platform-independent pipeline concepts to platform-specific ones. Step 3 produces the Acceleo template – the code generator that turns a model into actual pipeline files.
The key is what each step receives as input. Step 1 gets an existing PSM metamodel as a structural example and the platform documentation. Step 2 gets the PIM metamodel, a reference ATL file, and the Step 1 output. Step 3 gets the Step 1 output, a reference Acceleo template, and the platform documentation.
No input is there by accident. Each one serves a specific grounding purpose. This is context engineering, not casual prompting. The difference in output quality is large.
Is there a Vibe DevOps engineering tool?
There is one now – the MDDOAI is becoming a fully automated multi-agent system. The architecture is in place – an Orchestrator agent, a Retrieval agent, a Documentation Parser, six domain expert agents covering Software Architecture, PIM, PSM, CI/CD Pipeline, ATL, and Acceleo, and a Graph-RAG knowledge base that carries validated artifacts from one run to the next. What a human researcher did manually in our first experiments, these agents will do automatically.
So what comes next?
The vision is simple. Any CI/CD platform. Any team. No MDE expertise required.
Jenkinsfile is next. Then whatever platform comes after that. The constraint library grows with every run. The agents get sharper. No human in the middle, just a URL and a result. Vibe DevOps engineering is becoming what it was always meant to be: the last time anyone has to write a pipeline from scratch.
The vibe family is growing. Vibe coding, then vibe modelling, then vibe-driven engineering, now vibe DevOps engineering – already breaking language boundaries, becoming “izjūtizdarbinženierija” in Latvian. Each step takes conversational LLM generation further into the territory where correctness actually matters.
The stepsister is here. She doesn’t start from scratch. And now, neither do you.
– Moulik Arora, Akshat Dhingra, Uldis Karlovs-Karlovskis



